728x90
반응형
YOLO란?
YOLO는 You Only Look Once의 약자로 Object detection 분야에서 널리 알려진 모델이다.
처음으로 One-Stage-Detection (분류와 추론을 동시에 함)방법을 고안해 실시간으로 Object Detection이 가능하게 만들었다.
YOLO 특징
- 이미지를 분할하지 않고 이미지 한 장에서 분석이 가능합니다. (R-CNN과 같은 경우는 이미지 분할하여 CNN으로 추론)
- 다양한 전처리 모델과 인공 신경망을 결합해서 사용하는 이전 방식이 아닌 통합된 모델을 사용합니다.
- 실시간으로 객체를 탐지 할 수 있는 것이다. 기존의 Faster R-CNN보다 6배 빠른 성능을 보여줍니다.
YOLOv7 모델
YOLO(You Only Look Once) v7 모델은 YOLO 모델 제품군의 최신 제품입니다.
성능 (Performance)
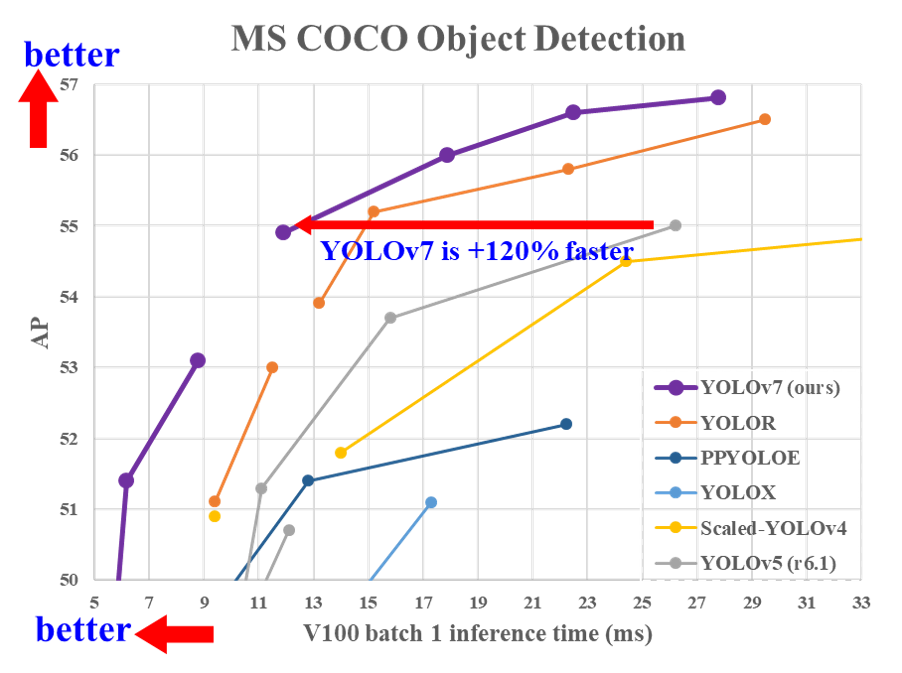
YOLO 모델은 단일 단계 객체 감지기입니다. YOLOv7 모델의 평가는 비교 가능한 실시간 물체 감지 모델보다 더 빠르고(x축) 더 높은 정확도(y축)로 추론한다는 것을 보여줍니다.
MS COCO
| Model | Test Size | AP test | AP 50test | AP 75test | batch 1 fps | batch 32 average time |
| YOLOv7 | 640 | 51.4% | 69.7% | 55.9% | 161 fps | 2.8 ms |
| YOLOv7-X | 640 | 53.1% | 71.2% | 57.8% | 114 fps | 4.3 ms |
| YOLOv7-W6 | 1280 | 54.9% | 72.6% | 60.1% | 84 fps | 7.6 ms |
| YOLOv7-E6 | 1280 | 56.0% | 73.5% | 61.2% | 56 fps | 12.3 ms |
| YOLOv7-D6 | 1280 | 56.6% | 74.0% | 61.8% | 44 fps | 15.0 ms |
| YOLOv7-E6E | 1280 | 56.8% | 74.4% | 62.1% | 36 fps | 18.7 ms |
아키텍처 (Architecture)
확장되고 효율적인 레이어 집선
그레디언트가 짧을수록 네트워크가 더 강력하게 학습할 수 있기 때문에 효율적으로 제어 (확장, 셔플, 병합)하는 E-ELAN 구조를 사용합니다.

모델 스케일링 기술
입력과 출력의 너비를 유지하면서 깊이만 스케일링 하는 기술을 제안하여 계산을 감소 시킵니다.

재매개변수화 계획
추론 비용을 늘리지 않고 정확도를 향상 시키는 방법입니다.

보조 헤드 거친에서 미세
Lead Head가 학습에 영향을 미치므로 Aux Head라도 Lead Head를 거친 것이 성능에 좋다는 것을 주장합니다.
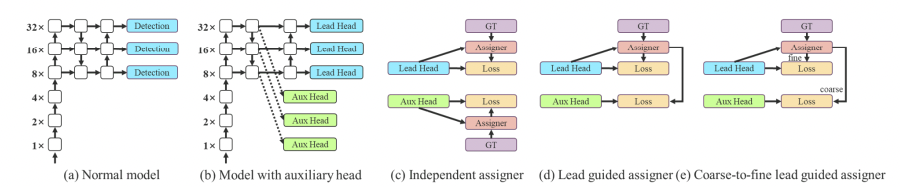
참고
728x90
반응형
'AI 인공지능 > AI Vision' 카테고리의 다른 글
| deep-text-recognition-benchmark 학습 (1) | 2022.12.01 |
|---|---|
| Craft Model 사용법 (0) | 2022.12.01 |
| YOLOv7를 활용한 Object Detection (0) | 2022.11.21 |
| 이미지 유사도 embedding (1) | 2021.12.29 |
| 패션 의류 분류 (Fashion Classification) (0) | 2021.09.15 |


