1. Hello, Seaborn
패키지 로드
- register_matplotlib_converters : matplotlib에 pandas 포맷터 및 변환기를 등록한다.
- %matplotlib inline : IPython 에서 제공하는 Rich output 대한 표현방식으로 도표와 같은 그림, 소리, 애니메이션들을 출력 (Rich output) 하는 것이다.
import pandas as pd
pd.plotting.register_matplotlib_converters()
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
print(">>> 로드 완료")데이터 로드
피파 랭킹 데이터를 로드해보자
인덱스 컬럼을 데이터열로 설정하고 형변환 여부를 True로 해준다.
import os
BASE_DIR = os.getcwd()
DATASET_DIR = os.path.join(BASE_DIR, 'datasets')fifa_filepath = os.path.join(DATASET_DIR, "fifa.csv")
fifa_data = pd.read_csv(fifa_filepath, index_col="Date", parse_dates=True)데이터 출력
데이터를 출력하여 잘 로드되었는지 head 부분만 출력해보자
Date가 Index 열로 되어있고 각 나라의 피파랭킹 순위가 나열되어 있다.
fifa_data.head()| ARG | BRA | ESP | FRA | GER | ITA | |
|---|---|---|---|---|---|---|
| Date | ||||||
| 1993-08-08 | 5.0 | 8.0 | 13.0 | 12.0 | 1.0 | 2.0 |
| 1993-09-23 | 12.0 | 1.0 | 14.0 | 7.0 | 5.0 | 2.0 |
| 1993-10-22 | 9.0 | 1.0 | 7.0 | 14.0 | 4.0 | 3.0 |
| 1993-11-19 | 9.0 | 4.0 | 7.0 | 15.0 | 3.0 | 1.0 |
| 1993-12-23 | 8.0 | 3.0 | 5.0 | 15.0 | 1.0 | 2.0 |
Plot를 활용하여 데이터 시각화
그래프 크기를 width x height 설정해주고 라인 차트로 출력해보자
plt.figure(figsize=(16,6))
sns.lineplot(data=fifa_data)<AxesSubplot:xlabel='Date'>

2. 라인차트
데이터 로드
위에서 하던 방식으로 이번에는 spotify 데이터를 로드해보자
spotify_filepath = os.path.join(DATASET_DIR, "spotify.csv")
spotify_data = pd.read_csv(spotify_filepath, index_col="Date", parse_dates=True)데이터 출력
상위 (head) 데이터 부분만 출력해본다.
spotify_data.head()| Shape of You | Despacito | Something Just Like This | HUMBLE. | Unforgettable | |
|---|---|---|---|---|---|
| Date | |||||
| 2017-01-06 | 12287078 | NaN | NaN | NaN | NaN |
| 2017-01-07 | 13190270 | NaN | NaN | NaN | NaN |
| 2017-01-08 | 13099919 | NaN | NaN | NaN | NaN |
| 2017-01-09 | 14506351 | NaN | NaN | NaN | NaN |
| 2017-01-10 | 14275628 | NaN | NaN | NaN | NaN |
이번에는 마지막 (tail) 데이터 부분만 출력해본다.
spotify_data.tail()| Shape of You | Despacito | Something Just Like This | HUMBLE. | Unforgettable | |
|---|---|---|---|---|---|
| Date | |||||
| 2018-01-05 | 4492978 | 3450315.0 | 2408365.0 | 2685857.0 | 2869783.0 |
| 2018-01-06 | 4416476 | 3394284.0 | 2188035.0 | 2559044.0 | 2743748.0 |
| 2018-01-07 | 4009104 | 3020789.0 | 1908129.0 | 2350985.0 | 2441045.0 |
| 2018-01-08 | 4135505 | 2755266.0 | 2023251.0 | 2523265.0 | 2622693.0 |
| 2018-01-09 | 4168506 | 2791601.0 | 2058016.0 | 2727678.0 | 2627334.0 |
Plot를 활용하여 데이터 시각화
그래프 크기를 width x height 설정해주고 라인 차트로 출력해보자
plt.figure(figsize=(14,6))
plt.title("Daily Global Streams of Popular Songs in 2017-2018")
sns.lineplot(data=spotify_data)<AxesSubplot:title={'center':'Daily Global Streams of Popular Songs in 2017-2018'}, xlabel='Date'>

컬럼만 출력해보자
list(spotify_data.columns)['Shape of You',
'Despacito',
'Something Just Like This',
'HUMBLE.',
'Unforgettable']
다음과 같이 두 개의 컬럼에 대해서만 별도로 설정하여 출력할 수 있다.
plt.figure(figsize=(14,6))
plt.title("Daily Global Streams of Popular Songs in 2017-2018")
sns.lineplot(data=spotify_data['Shape of You'], label="Shape of You")
sns.lineplot(data=spotify_data['Despacito'], label="Despacito")
plt.xlabel("Date")Text(0.5, 0, 'Date')

한 개의 데이터만 출력해보자.
sns.lineplot(data=spotify_data['Shape of You'], label="Shape of You")
3. 바 차트와 Heatmaps
데이터 로드
위에서 하던 방식으로 이번에는 "비행 지연을 추적하는 미국 교통부의 데이터 세트"로 로드해보자.
열은 월단위로 만들어본다.
flight_filepath = os.path.join(DATASET_DIR, "flight_delays.csv")
flight_data = pd.read_csv(flight_filepath, index_col="Month")데이터 출력
flight_data| AA | AS | B6 | DL | EV | F9 | HA | MQ | NK | OO | UA | US | VX | WN | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Month | ||||||||||||||
| 1 | 6.955843 | -0.320888 | 7.347281 | -2.043847 | 8.537497 | 18.357238 | 3.512640 | 18.164974 | 11.398054 | 10.889894 | 6.352729 | 3.107457 | 1.420702 | 3.389466 |
| 2 | 7.530204 | -0.782923 | 18.657673 | 5.614745 | 10.417236 | 27.424179 | 6.029967 | 21.301627 | 16.474466 | 9.588895 | 7.260662 | 7.114455 | 7.784410 | 3.501363 |
| 3 | 6.693587 | -0.544731 | 10.741317 | 2.077965 | 6.730101 | 20.074855 | 3.468383 | 11.018418 | 10.039118 | 3.181693 | 4.892212 | 3.330787 | 5.348207 | 3.263341 |
| 4 | 4.931778 | -3.009003 | 2.780105 | 0.083343 | 4.821253 | 12.640440 | 0.011022 | 5.131228 | 8.766224 | 3.223796 | 4.376092 | 2.660290 | 0.995507 | 2.996399 |
| 5 | 5.173878 | -1.716398 | -0.709019 | 0.149333 | 7.724290 | 13.007554 | 0.826426 | 5.466790 | 22.397347 | 4.141162 | 6.827695 | 0.681605 | 7.102021 | 5.680777 |
| 6 | 8.191017 | -0.220621 | 5.047155 | 4.419594 | 13.952793 | 19.712951 | 0.882786 | 9.639323 | 35.561501 | 8.338477 | 16.932663 | 5.766296 | 5.779415 | 10.743462 |
| 7 | 3.870440 | 0.377408 | 5.841454 | 1.204862 | 6.926421 | 14.464543 | 2.001586 | 3.980289 | 14.352382 | 6.790333 | 10.262551 | NaN | 7.135773 | 10.504942 |
| 8 | 3.193907 | 2.503899 | 9.280950 | 0.653114 | 5.154422 | 9.175737 | 7.448029 | 1.896565 | 20.519018 | 5.606689 | 5.014041 | NaN | 5.106221 | 5.532108 |
| 9 | -1.432732 | -1.813800 | 3.539154 | -3.703377 | 0.851062 | 0.978460 | 3.696915 | -2.167268 | 8.000101 | 1.530896 | -1.794265 | NaN | 0.070998 | -1.336260 |
| 10 | -0.580930 | -2.993617 | 3.676787 | -5.011516 | 2.303760 | 0.082127 | 0.467074 | -3.735054 | 6.810736 | 1.750897 | -2.456542 | NaN | 2.254278 | -0.688851 |
| 11 | 0.772630 | -1.916516 | 1.418299 | -3.175414 | 4.415930 | 11.164527 | -2.719894 | 0.220061 | 7.543881 | 4.925548 | 0.281064 | NaN | 0.116370 | 0.995684 |
| 12 | 4.149684 | -1.846681 | 13.839290 | 2.504595 | 6.685176 | 9.346221 | -1.706475 | 0.662486 | 12.733123 | 10.947612 | 7.012079 | NaN | 13.498720 | 6.720893 |
바 차트
Spirit Airlines 항공편의 월별 평균 도착 지연을 보여주는 막대 차트로 그려보자.
plt.figure(figsize=(10,6))
plt.title("Average Arrival Delay for Spirit Airlines Flights, by Month")
sns.barplot(x=flight_data.index, y=flight_data['NK'])
plt.ylabel("Arrival delay (in minutes)")Text(0, 0.5, 'Arrival delay (in minutes)')

Heatmap
Heatmap은 각 셀은 해당 값에 따라 색상으로 구분되어 시각화해주는 유용한 차트이다.
plt.figure(figsize=(14,7))
plt.title("Average Arrival Delay for Each Airline, by Month")
sns.heatmap(data=flight_data, annot=True)
plt.xlabel("Airline")Text(0.5, 42.0, 'Airline')

4. 산점도 그래프 (Scatter plots)
데이터 로드
위에서 하던 방식으로 이번에는 보험 데이터를 로드해보자.
insurance_filepath = os.path.join(DATASET_DIR, "insurance.csv")
insurance_data = pd.read_csv(insurance_filepath)insurance_data.head()| age | sex | bmi | children | smoker | region | charges | |
|---|---|---|---|---|---|---|---|
| 0 | 19 | female | 27.900 | 0 | yes | southwest | 16884.92400 |
| 1 | 18 | male | 33.770 | 1 | no | southeast | 1725.55230 |
| 2 | 28 | male | 33.000 | 3 | no | southeast | 4449.46200 |
| 3 | 33 | male | 22.705 | 0 | no | northwest | 21984.47061 |
| 4 | 32 | male | 28.880 | 0 | no | northwest | 3866.85520 |
산점도 그래프 (Scatter plots)
체질량지수 (BMI)에 따른 부과되는 보험 비용(charges)을 시각화해보자.
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'])<AxesSubplot:xlabel='bmi', ylabel='charges'>

위의 산점도는 체질량 지수(BMI)와 보험료가 양의 상관 관계가 있음을 예상할 수 있다.
(BMI가 높은 고객은 일반적으로 보험 비용도 더 많이 지불하는 경향이라는 것을 알 수 있다.)
이 관계의 강도를 다시 확인하기 위해 회귀선 또는 데이터에 가장 적합한 선을 추가할 수 있다.
regplot 함수를 통하여 확인해보자.
sns.regplot(x=insurance_data['bmi'], y=insurance_data['charges'])<AxesSubplot:xlabel='bmi', ylabel='charges'>

Color-coded scatter plots
세 변수 간의 관계를 표시할 수 있다. 이를 수행하기 위해 포인트를 색상으로 구분해본다.
흡연이 BMI와 보험 비용 간의 관계에 어떤 영향을 미치는지 표현하기 위해 다음과 같이 설정하여 시각해 볼 수 있다.
sns.scatterplot(x=insurance_data['bmi'], y=insurance_data['charges'], hue=insurance_data['smoker'])<AxesSubplot:xlabel='bmi', ylabel='charges'>
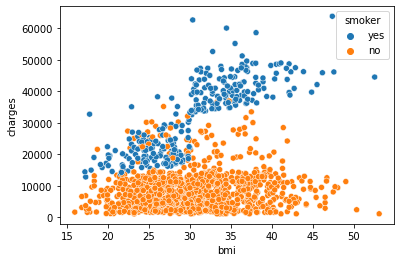
위와 했던 동일한 방식으로 적합한 선을 추가하여 확인해 볼 수 있다.
sns.lmplot(x="bmi", y="charges", hue="smoker", data=insurance_data)<seaborn.axisgrid.FacetGrid at 0x21393f51f48>

swarmplot을 활용하여 범주형 그래프로 표현해보자.
sns.swarmplot(x=insurance_data['smoker'],
y=insurance_data['charges'])<AxesSubplot:xlabel='smoker', ylabel='charges'>

5. 분포 (Distributions)
데이터 로드
위에서 하던 방식으로 이번에는 붓꽃 데이터를 로드해보자.
iris_filepath = os.path.join(DATASET_DIR, "iris.csv")
iris_data = pd.read_csv(iris_filepath, index_col="Id")
iris_data.head()Histograms
붓꽃의 꽃잎 길이가 어떻게 변하는지 보기 위해 히스토그램을 만들어보자.
sns.distplot(a=iris_data['Petal Length (cm)'], kde=False)<AxesSubplot:xlabel='Petal Length (cm)'>

밀도 그래프 (Density plots)
밀도 그래프를 그려보자. shade 라는 옵션을 설정하여 색을 채워주도록 한다.
sns.kdeplot(data=iris_data['Petal Length (cm)'], shade=True)<AxesSubplot:xlabel='Petal Length (cm)', ylabel='Density'>

2D KDE plots
2차원으로 그려보자.
sns.jointplot(x=iris_data['Petal Length (cm)'], y=iris_data['Sepal Width (cm)'], kind="kde")<seaborn.axisgrid.JointGrid at 0x21396539048>
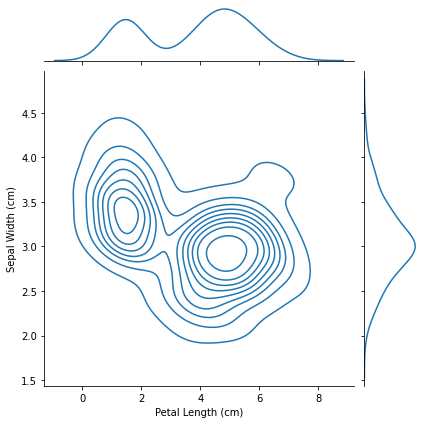
Color-coded plots
3개의 데이터셋을 하나의 차트로 그려보자.
iris_set_filepath = os.path.join(DATASET_DIR, "iris_setosa.csv")
iris_ver_filepath = os.path.join(DATASET_DIR, "iris_versicolor.csv")
iris_vir_filepath = os.path.join(DATASET_DIR, "iris_virginica.csv")
iris_set_data = pd.read_csv(iris_set_filepath, index_col="Id")
iris_ver_data = pd.read_csv(iris_ver_filepath, index_col="Id")
iris_vir_data = pd.read_csv(iris_vir_filepath, index_col="Id")
iris_ver_data.head()sns.distplot(a=iris_set_data['Petal Length (cm)'], label="Iris-setosa", kde=False)
sns.distplot(a=iris_ver_data['Petal Length (cm)'], label="Iris-versicolor", kde=False)
sns.distplot(a=iris_vir_data['Petal Length (cm)'], label="Iris-virginica", kde=False)
plt.title("Histogram of Petal Lengths, by Species")
plt.legend()<matplotlib.legend.Legend at 0x213969c1a08>

sns.kdeplot(data=iris_set_data['Petal Length (cm)'], label="Iris-setosa", shade=True)
sns.kdeplot(data=iris_ver_data['Petal Length (cm)'], label="Iris-versicolor", shade=True)
sns.kdeplot(data=iris_vir_data['Petal Length (cm)'], label="Iris-virginica", shade=True)
plt.title("Distribution of Petal Lengths, by Species")Text(0.5, 1.0, 'Distribution of Petal Lengths, by Species')

6. Plot 타입 스타일 변경
seabor 스타일 변경
spotify_filepath = os.path.join(DATASET_DIR, "spotify.csv")
spotify_data = pd.read_csv(spotify_filepath, index_col="Date", parse_dates=True)
plt.figure(figsize=(12,6))
sns.lineplot(data=spotify_data)<AxesSubplot:xlabel='Date'>

'데이터 분석' 카테고리의 다른 글
| python 파일 용량이 큰 파일을 읽을 경우 (0) | 2022.09.01 |
|---|---|
| Pandas 구분자로 되어 있는 행 여러 줄 행으로 만들기 (0) | 2022.03.03 |
| Pandas 를 활용해보자 (0) | 2022.03.02 |