

View
LLM 답변이 엉뚱한 결과를 내놓는다면 90%는 retrieval이 잘못된 경우다. 모델을 탓하기 전에 검색부터 의심해야 한다. 그리고 검색이라는 것이 임베딩 한 번 박아 넣는다고 끝나는 일이 아니라는 사실은, RAG를 한 번이라도 돌려본 사람이라면 모두 안다.
처음에는 다들 비슷하게 시작한다. OpenAI 임베딩을 뽑아 pgvector나 Qdrant에 넣고, 코사인 유사도로 top-k를 뽑으면 알아서 잘 동작할 것이라 기대한다. 그러나 막상 운영에 들어가면 사용자가 "PRD-2024-031 문서를 찾아달라"고 했는데 엉뚱한 결과가 나오고, "환불 정책"을 검색했는데 정확한 정책 문서 대신 환불 관련 잡담 글이 1등을 차지한다. 이것이 바로 시맨틱 검색만 사용할 때 무너지는 전형적 사례다.
이 글에서는 BM25, 시맨틱 검색, 하이브리드 검색의 차이를 실전 관점에서 정리하고, 왜 AI 시대에 retrieval이 LLM 자체보다 중요해지는지까지 풀어본다. 2026년 기준 최신 기법(contextual retrieval, GraphRAG, late-interaction)도 함께 다룬다.
검색 엔진이 갑자기 다시 중요해진 이유

출처: pryon.com
검색이 다시 주목받게 된 것은 LLM이 등장한 이후부터다. 정확히 말하면 RAG (Retrieval-Augmented Generation) 패턴이 표준이 되면서부터 retrieval 품질이 곧 답변 품질이 되었다.
원리는 단순하다. LLM은 자기 가중치(weights) 안에 학습된 지식과 프롬프트로 들어온 컨텍스트만으로 답한다. 사내 문서, 최신 뉴스, 고객 데이터 같은 정보는 학습에 포함되어 있지 않으므로 retrieval로 떠먹여 주어야 한다. 떠먹여 준 자료가 잘못되면 어떻게 되는가? 모델이 아무리 똑똑해도 답이 망가진다. 결국 옛날의 "garbage in, garbage out" 원칙이 LLM 시대에 부활한 셈이다.
검색이 부실하면 LLM이 아무리 좋아도 답이 망가진다
GPT-4든 Claude Opus든 Gemini Ultra든 컨텍스트가 잘못 들어가면 모두 똑같이 헛소리를 한다. 실제로 RAG 실패를 분석해 보면 대부분의 잘못된 답변이 "관련 문서가 retrieval 단계에서 아예 잡히지 않은 경우"다. 모델이 답을 지어낸 것이 아니라 답을 만들 재료 자체가 없었던 것이다.
흔한 실패 패턴은 다음과 같다.
- 사용자가 "환불 정책"을 물었는데 retrieval이 "환불 후기" 글을 1등으로 뽑는다 → 모델이 후기 기준으로 답변한다
- 코드 스니펫에서 함수명을 정확히 검색해야 하는데 시맨틱 검색이 "비슷한 함수"를 더 위에 올린다
- 한국어 형태소 분석을 하지 않아 "삼성전자"와 "삼성"이 다른 토큰으로 처리된다
hallucination을 줄이는 가장 빠른 방법은 retrieval 개선이다
hallucination을 줄이려고 모델 fine-tuning부터 알아보는 사람이 많은데, 비용 대비 효과로 보면 retrieval을 손보는 쪽이 훨씬 빠르다. 정답이 들어 있는 문서 청크가 LLM 컨텍스트에 들어가기만 하면, 웬만한 모델은 그것을 잘 인용해 답한다. 정답 청크를 retrieval이 찾지 못하면 무슨 짓을 해도 답이 나오지 않는다.
키워드 검색(BM25)이 아직도 살아있는 이유
출처: Daily Dose of Data Science (217KB)
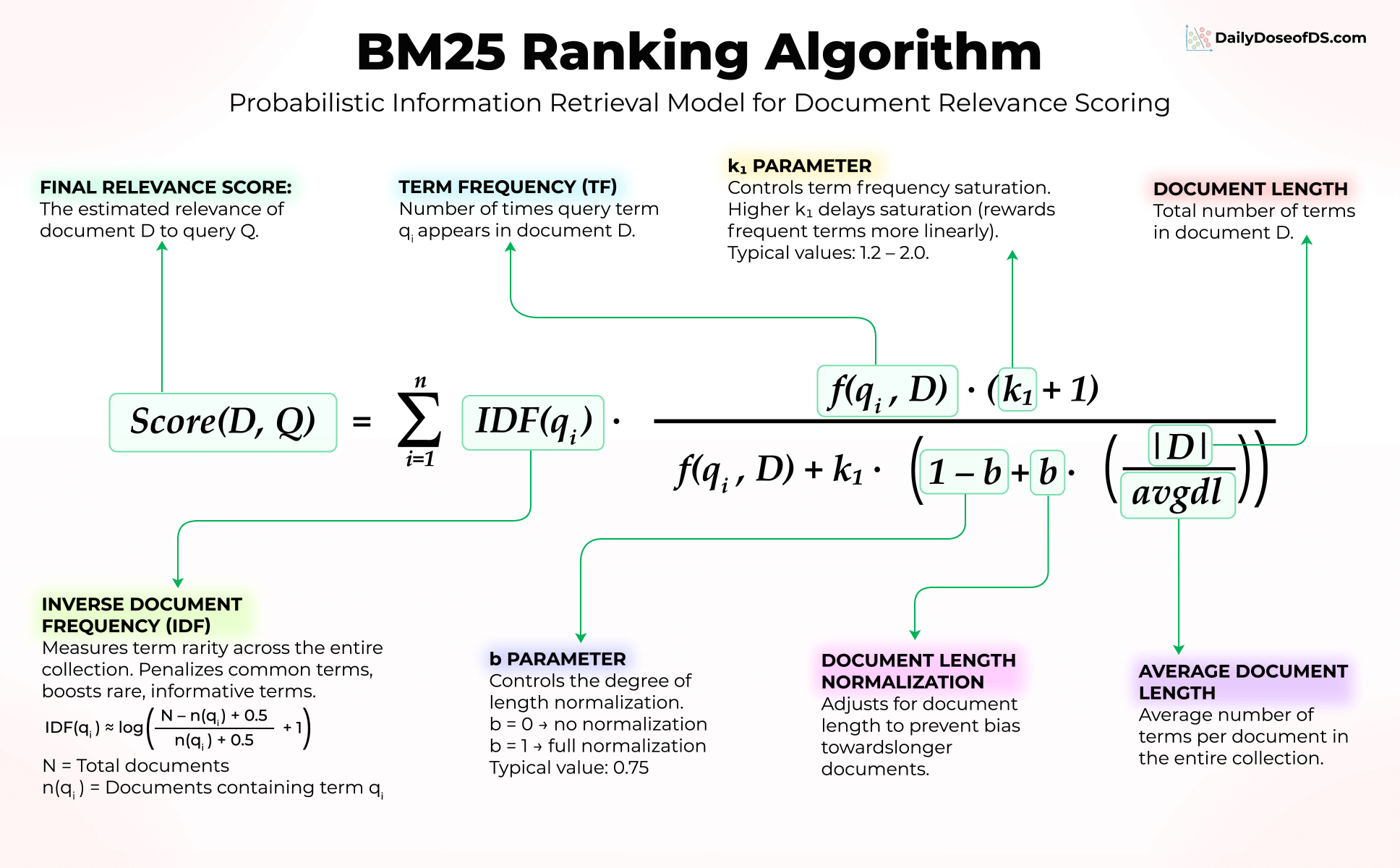
BM25는 1994년에 등장한 알고리즘이다. 그런데 2026년 지금도 Elasticsearch, OpenSearch, Vespa, Tantivy 같은 거의 모든 검색 엔진의 기본값이다. 30년 된 알고리즘이 왜 사라지지 않았을까? 답은 단순하다. 키워드 매칭에서 BM25를 이기는 알고리즘이 좀처럼 없다.
BM25는 TF-IDF의 진화형이다. 한 문서에 쿼리 단어가 자주 나오면 점수가 올라가고(term frequency), 그 단어가 전체 코퍼스에서 희귀하면 점수가 더 올라가며(inverse document frequency), 문서 길이로 정규화도 한다. 이렇게 단순한데도 정확한 단어 매칭 시나리오에서는 임베딩 기반 검색을 자주 이긴다.
BM25 수식을 외우지 않아도 된다, 직관만 잡으면 된다
수식을 외울 필요는 없다. 핵심 직관 세 가지만 잡으면 충분하다.
- 희귀한 단어가 매치되면 점수 폭등: "신청서 양식 PRD-2024-031" 같은 쿼리에서 "PRD-2024-031"은 코퍼스에 거의 등장하지 않는 토큰이다. BM25는 이 단어가 매치되면 점수를 크게 부여한다.
- 쿼리 단어가 여러 번 나와도 점수가 무한정 오르지 않는다: log 스케일과 비슷하게 saturate된다. "고양이 고양이 고양이"가 "고양이"보다 약간만 점수가 높다.
- 긴 문서가 단순히 길다는 이유로 유리해지지 않도록 정규화: 기본 파라미터 b=0.75 정도가 평균적이다.
Elasticsearch / OpenSearch / Tantivy 같은 엔진들은 모두 BM25 기반이다
사용 중인 검색 인프라가 무엇이든 BM25는 무료로 깔려 있다. Elasticsearch의 기본 similarity가 BM25다. PostgreSQL의 tsvector 기본 ts_rank는 BM25가 아니라 단순 TF 기반이라 IDF/문서길이 정규화가 빠져 있다. BM25를 제대로 쓰려면 ParadeDB나 VectorChord-BM25 같은 익스텐션을 박아야 한다.
한국어에서 BM25를 쓸 때 형태소 분석기를 박지 않으면 망한다
영어 BM25를 그대로 한국어에 가져다 쓰면 그야말로 망한다. 영어는 띄어쓰기가 단어 경계라 토크나이징이 거의 자동이지만, 한국어는 조사가 붙고 어미가 붙으며 합성어가 마구 만들어진다.
예를 들어 "삼성전자가 반도체를 만든다"라는 문서가 있을 때, 단순 띄어쓰기 토크나이저는 "삼성전자가", "반도체를", "만든다"를 토큰으로 만든다. 사용자가 "삼성전자"로 검색하면 "삼성전자가"와 매치되지 않는다.
해결책은 형태소 분석기를 박는 것이다. mecab-ko, nori (Elasticsearch 한국어 분석기), khaiii, kiwi 같은 것을 골라 쓰면 된다. nori는 Elasticsearch에 공식 플러그인으로 들어가 있어 가장 무난하다. 이것을 박지 않고 한국어 BM25를 한다는 것은 그저 검색을 망치겠다는 선언이다.
시맨틱 검색(Semantic / Dense Retrieval)이 잘하는 것
시맨틱 검색은 텍스트를 벡터(보통 768 ~ 3072 차원)로 임베딩하고, 쿼리 벡터와 문서 벡터들 사이의 코사인 유사도(또는 내적)로 가까운 결과를 뽑는 방식이다. dense retrieval이라고도 부른다.
강점은 명확하다. 단어가 달라도 의미가 비슷하면 잡아낸다. "자동차 보험"으로 검색해도 "차량 보험" 문서가 함께 잡힌다. "환불"로 검색하면 "취소 후 입금" 문서까지 잡힌다. BM25는 이것이 절대 되지 않는다.
임베딩 모델 고르는 기준
2026년 기준으로 임베딩 모델 선택지가 너무 많다. 정리하면 다음과 같다.
- OpenAI text-embedding-3-small / large: 무난한 기본값. multilingual이 잘 되고 한국어도 쓸 만하다. 비용도 적당하다.
- BGE (BAAI General Embedding) M3: 오픈소스 중 최강 라인. 자체 호스팅 가능, multilingual 지원, MTEB 상위권이다.
- E5-mistral-7b-instruct: 큰 모델 기반이라 정확도는 좋으나 추론 비용이 크다.
- Cohere embed-multilingual-v3: 한국어 포함 100개 이상의 언어를 지원하며, API 비용도 합리적이다.
- 한국어 특화 모델: KoSimCSE, ko-sbert 같은 모델 — 도메인이 맞으면 OpenAI보다 좋은 결과가 나오기도 한다.
평가는 MTEB Leaderboard에서 한국어(또는 multilingual) 카테고리를 보면 된다. 다만 벤치마크 1등이 자기 데이터에서도 1등이라는 보장은 없으므로, 실제 자기 코퍼스 일부로 검증을 한 번 돌려보는 것이 답이다.
청킹 전략이 잘못되면 시맨틱 검색도 망한다
임베딩 모델을 잘 골랐다고 끝이 아니다. 청킹(chunking)이 잘못되면 검색이 모두 망가진다. 왜일까? 임베딩은 청크 단위로 만들어지는데, 청크가 너무 크면 의미가 희석되고 너무 작으면 컨텍스트가 끊기기 때문이다.
흔한 청킹 함정은 다음과 같다.
- 고정 길이로 자르기: 500 토큰씩 단순 분할 → 문장 중간에서 잘림
- 너무 작은 청크: 100 토큰씩 자르면 표/리스트 단위로 의미가 파괴됨
- 메타데이터 누락: 청크에 출처 문서명, 섹션 제목, 날짜 같은 것을 박지 않으면 검색 결과 정렬/필터가 모두 동작하지 않음
권장은 의미 단위 청킹(semantic chunking) 또는 문단/섹션 단위 청킹이다. 그리고 청크에 헤더를 prepend하는 것이 거의 항상 도움이 된다. Anthropic이 발표한 contextual retrieval 기법이 바로 이 아이디어인데, 청크 앞에 50~100 토큰짜리 문서 컨텍스트 요약을 붙이면 검색 실패율이 35% 정도 줄어든다고 한다 (BM25까지 결합하면 49%, 리랭커까지 얹으면 67%).
벡터 DB 종류 (pgvector, Qdrant, Weaviate, Pinecone, Milvus)
벡터 DB 선택은 데이터 규모와 운영 인력에 따라 갈린다.
| 종류 | 장점 | 약점 |
| pgvector | 이미 PostgreSQL을 쓰면 0설정, 트랜잭션 OK | 1000만 벡터를 넘어가면 느려짐 |
| Qdrant | 빠르고 자체 호스팅이 무난하며 필터가 강함 | 운영 학습 곡선 |
| Weaviate | 하이브리드 검색 내장, GraphQL API | 메모리를 많이 먹음 |
| Pinecone | 매니지드 서비스, 운영 부담 0 | 비싸고 락인 |
| Milvus | 대규모 (10억 벡터) 가능, 오픈소스 | 클러스터 운영이 빡셈 |
100만 벡터 이하라면 pgvector로 시작해도 충분하다. 그 이상으로 가면 Qdrant나 Weaviate를 보면 된다.
하이브리드 검색(Hybrid Search)이 답인 이유
출처: opensearch.org
BM25는 단어 매칭에 강하고, 시맨틱은 의미 매칭에 강하다. 이 둘의 약점이 정확히 반대다. 그래서 둘을 합치면 거의 항상 둘 중 하나만 쓰는 것보다 결과가 좋다. 이것이 하이브리드 검색이다.
BEIR 벤치마크 결과를 보면 거의 모든 도메인에서 하이브리드 검색이 BM25 단독, dense 단독을 모두 이긴다. 차이가 작은 도메인도 있고 큰 도메인도 있는데, 평균적으로 nDCG@10 기준 5~15% 정도의 향상이 나온다.
RRF가 가성비 좋은 기본값이다
하이브리드 결합 방법 중 가장 무난한 것이 RRF (Reciprocal Rank Fusion)다. 수식은 진짜 단순하다.
RRF_score(d) = sum( 1 / (k + rank_i(d)) )
각 검색 시스템(BM25, dense)에서 문서 d의 순위(rank)를 가져와 1/(k+rank) 형태로 합치는 방식이다. k는 보통 60이다. 핵심 장점은 점수 정규화를 신경 쓰지 않아도 된다는 점이다. BM25 점수와 코사인 유사도 점수는 스케일이 완전히 달라서 단순 가중합을 하면 한쪽이 지배해 버리는데, RRF는 순위만 사용하므로 그 문제가 사라진다.
def rrf_combine(results_bm25, results_dense, k=60):
scores = {}
for rank, doc in enumerate(results_bm25, start=1):
scores[doc.id] = scores.get(doc.id, 0) + 1.0 / (k + rank)
for rank, doc in enumerate(results_dense, start=1):
scores[doc.id] = scores.get(doc.id, 0) + 1.0 / (k + rank)
return sorted(scores.items(), key=lambda x: -x[1])
이 함수 하나만 짜면 하이브리드 검색이 일단 굴러간다. 막 만든 것치고는 성능이 깜짝 놀랄 정도다.
점수 정규화를 하지 않으면 sparse가 dense를 짓밟는다
RRF 말고 점수 가중합 (Convex Combination) 방식도 많이 쓴다. score = alpha dense + (1-alpha) sparse 식인데, 이때 두 점수의 스케일이 맞지 않으면 망한다.
BM25 점수는 보통 0~50 범위이고, 코사인 유사도는 -1~1 범위다. 이것을 그냥 더하면 BM25의 영향이 압도적이다. 그래서 min-max 정규화나 z-score 정규화를 한 다음에 합쳐야 한다. 이것이 귀찮아서 그냥 RRF를 쓰는 사람이 많다.
alpha 값은 0.5에서 시작해 자기 데이터에 맞게 튜닝한다. 키워드 검색이 더 중요한 도메인(법률, 의료, 코드)은 alpha를 낮추고, 의미 매칭이 더 중요한 도메인(고객 지원, 자연어 Q&A)은 alpha를 높인다.
하이브리드를 만들기 가장 쉬운 스택
2026년 기준 하이브리드 검색을 가장 쉽게 만드는 옵션은 다음과 같다.
- Elasticsearch 8+: BM25와 dense vector 검색이 모두 네이티브로 지원된다. RRF 쿼리도 8.8부터 들어왔다. _search/hybrid 엔드포인트 한 방이다.
- Weaviate: hybrid search가 기본 API다. alpha 파라미터 한 줄로 조정한다.
- OpenSearch: 2.10+에서 hybrid search 파이프라인을 지원한다.
- Qdrant + 별도 BM25: Qdrant는 dense만 다루므로 BM25는 Tantivy나 Elasticsearch로 따로 운영하고 결과를 합치는 형태다.
- Vespa: 처음부터 하이브리드를 염두에 두고 만들어진 엔진이다. 러닝 커브가 빡세지만 강력하다.

그래서 요즘 검색은 어디까지 발전했는가
하이브리드까지가 기본이고, 그 위에 얹는 기법들이 많이 등장했다. 모두 알 필요는 없으나 이름은 알아두어야 한다.
- Reranking: top-k (보통 50~100) 결과를 cross-encoder 리랭커로 다시 정렬한다. Cohere Rerank, BGE reranker, Jina reranker 같은 것이 있다. retrieval에서 50개를 뽑고 리랭커로 top-5를 뽑는 패턴이 정석이다. 정확도가 크게 오르지만 latency가 100~500ms 추가된다. 중요한 쿼리에만 쓰는 것이 답이다.
- Late interaction (ColBERT, ColBERTv2): 쿼리와 문서를 토큰 단위로 매칭한다. dense retrieval보다 정밀하고 cross-encoder보다 빠르다. 인덱스 크기가 큰 것이 단점이다. 큰 코퍼스에서는 부담스럽다.
- SPLADE (Sparse 임베딩): BM25처럼 sparse 벡터지만 학습된 가중치를 쓴다. BM25보다 좋고 dense보다 해석이 가능하다. Naver Labs Europe에서 만들었다.
- Contextual Retrieval: Anthropic이 띄운 기법이다. 청크 앞에 "이 청크는 X 문서의 Y 섹션이고 Z를 다룬다" 식의 컨텍스트를 LLM으로 만들어 prepend한다. 검색 실패율 35% 감소가 보고되었다.
- GraphRAG: 지식 그래프와 벡터 검색을 결합한 방식이다. Microsoft가 띄웠다. 엔티티 간 관계까지 활용해 multi-hop 질문에 강하다. 인덱싱 비용이 크다.
- Agentic Search: LLM이 직접 쿼리를 reformulate하고, 검색 결과를 보고 추가 쿼리를 날리며, 자가평가까지 한다. 비용은 크지만 어려운 질문에 강하다.
다 하면 좋지만 다 하면 비싸다, 우선순위를 정리한다
전부 박으면 답변 정확도는 올라가지만 비용/지연/운영 부담이 폭발한다. 가성비 우선순위는 다음과 같다.
- BM25 한 줄 추가 (이미 dense만 쓰고 있다면 가장 빠른 win)
- 하이브리드 결합 (RRF)
- 청킹 전략 개선 + 메타데이터 보강
- 리랭커 도입 (top-k에만)
- contextual retrieval (인덱싱 비용을 감수할 수 있다면)
- ColBERT, GraphRAG, agentic search는 그 다음 순서다
2026년 기준 가장 가성비 좋은 조합
작은~중간 규모 RAG라면 다음 조합이 거의 답이다.
- 형태소 분석기를 박은 BM25
- OpenAI text-embedding-3-small 또는 BGE-M3 임베딩
- RRF로 하이브리드 결합
- top-50을 뽑고 리랭커로 top-5 추출
- 컨텍스트 윈도우에 들어갈 청크에 출처 메타데이터 함께 포함
이것만 해도 어지간한 RAG는 무너지지 않는다. 더 잘하려면 contextual retrieval을 추가한다. 그 위는 도메인 특수성에 따라 결정한다.
AI 시대, 검색이 LLM보다 중요해지는 이유

요즘 모델 품질이 평준화되는 중이다. Claude 4.7, GPT-5, Gemini 3 Pro가 모두 비슷비슷하다. 어떤 벤치마크는 A가 이기고 어떤 것은 B가 이긴다. 이것이 무엇을 뜻하는가 하면, 모델 자체로는 차별화가 점점 어려워진다는 것이다. 차별화는 어디서 나오는가? 컨텍스트에서 나온다. 그리고 컨텍스트는 retrieval에서 나온다.
비즈니스 관점에서도 동일하다. LLM API 비용은 입력 토큰 수에 비례한다. 검색이 정확하면 진짜 필요한 청크 5개만 보내면 된다. 검색이 부실하면 안전마진을 두려고 50개를 보내야 한다. 비용이 10배 차이가 난다. 같은 답변 품질을 더 적은 토큰으로 만드는 회사가 그대로 이긴다.
"더 큰 모델"보다 "더 좋은 검색"이 ROI가 크다
GPT-5 Opus 대신 GPT-5 Sonnet을 쓰면 비용이 1/5이다. 답변 품질은 어떨까? retrieval이 좋으면 거의 차이가 없다. retrieval이 부실하면 큰 모델로도 살리지 못한다. 결국 같은 비용 예산 안에서 retrieval에 쓰는 것이 모델 업그레이드보다 ROI가 크다.
평가 지표도 정착되는 중이다. retrieval 자체는 nDCG@10, MRR, recall@k 같은 지표다. 답변 품질은 faithfulness (인용 정확도), answer relevance (질문 관련성)다. Ragas 같은 프레임워크의 표준화가 진행 중이다.
검색이 곧 제품 차별화의 해자(moat)가 된다
LLM API는 누구나 부를 수 있다. 시맨틱 검색도 라이브러리만 있으면 누구나 깔 수 있다. 차이를 만드는 것은 자기 도메인 데이터에 맞는 retrieval 튜닝이다. 청킹 전략, 메타데이터 설계, 가중치 튜닝, 리랭커 학습 데이터 — 이것들이 모두 노하우이고 데이터이며 결국 해자다.
옛날에 구글이 검색으로 해자를 만들었던 것처럼, 2026년 AI 제품에서는 도메인 특화 retrieval이 새로운 해자다. 모델은 갈아끼울 수 있어도 잘 튜닝된 retrieval은 베끼지 못한다.
한 줄 요약: 하이브리드 검색부터 챙겨라
긴 글을 끝까지 보았으니 핵심만 다시 정리한다.
- BM25는 단어 매칭, 시맨틱은 의미 매칭이다. 둘 다 약점이 정확히 반대다.
- 하이브리드 검색이 거의 항상 둘 다보다 잘 나온다. RRF가 시작점이다.
- AI 시대 차별화는 LLM이 아니라 retrieval에서 나온다. 같은 모델로도 retrieval이 다르면 결과는 천지 차이다.
지금 RAG를 돌리고 있다면 가장 빠른 개선 순서는 이렇다. 첫째, dense만 쓰고 있다면 BM25를 추가하고 RRF로 결합한다. 둘째, 한국어 코퍼스라면 형태소 분석기(nori, mecab-ko, kiwi)를 박았는지 확인한다. 셋째, 청크 앞에 문서 컨텍스트를 prepend해 본다 (Anthropic contextual retrieval). 넷째, 중요한 쿼리에만 리랭커를 얹는다.
이 네 가지만 해도 답변 품질의 체감 차이가 크다. 모델 업그레이드를 검토하기 전에 하이브리드 검색부터 손봐야 한다. 결국 AI 시대 RAG의 ROI는 더 큰 LLM이 아니라 더 좋은 검색에서 나온다. 그것이 답이다.
'AI LLM' 카테고리의 다른 글
| Claude Superpowers Skills 브레인스토밍, 코드 설계, 코드 리뷰까지 (0) | 2026.05.09 |
|---|---|
| LLM을 코드를 다른 언어로 컨버팅 어려운 이유 (학계 논문 인용) (0) | 2026.05.09 |
| TypeScript 끝판왕 Matt Pocock, 본인 .claude/skills 폴더를 통째로 공개하다 (0) | 2026.05.01 |
| 트위터 Grok은 무엇이고 왜 모두가 멘션을 다는가? (0) | 2026.04.27 |
| Claude Code "Auto Mode"란 무엇인가 — --dangerously-skip-permissions 없이 자동화를 실행하는 방법 (0) | 2026.04.26 |
