DeepSpeed
개요
큰 모델은 순수한 데이터 병렬 처리로 쉽게 메모리가 부족하고 모델 병렬 처리를 사용하기 어렵다.
DeepSpeed는 이러한 문제를 해결하여 모델 개발 및 훈련을 가속화 시킬 수 있다.
DeeSpeed란?
DeeSpeed API는 PyTorch의 경량 래퍼이다. 새로운 플랫폼을 배우지 않고도 PyTorch에서 좋아하는 모든 것을 사용할 수 있는 장점이 있다. DeepSpeed는 모델 개발에 집중할 수 있도록 분산 훈련, 혼합 정밀도 등 하이퍼파라미터를 관리한다.
가장 중요한 것은 DeepSpeed의 고유한 효율성 및 효율성 이점을 활용하여 PyTorch 모델에 대한 몇 줄의 코드 변경만으로 속도와 확장성을 높일 수 있다.
속도
DeepSpeed는 컴퓨팅/통신/메모리/IO에 대한 효율성 최적화와 고급 하이퍼파라미터 튜닝 및 옵티마이저에 대한 효율성 최적화의 조합을 통해 고성능 및 빠른 컨버전스를 달성한다.
- DeepSpeed는 BERT-large를 1024 V100 GPU(64 DGX-2 상자)를 사용하여 44분 만에, 256 GPU(16 DGX-2 상자)를 사용하여 2.4시간 만에 패리티로 훈련한다.
BERT-큰 훈련 시간
| 장치 | 훈련 시간 | |
| V100 GPU 1024개 | 딥스피드 | 44 분 |
| V100 GPU 256개 | 딥스피드 | 2.4 시간 |
| V100 GPU 64개 | 딥스피드 | 8.68 시간 |
| V100 GPU 16개 | 딥스피드 | 33.22 시간 |
메모리 효율성
DeepSpeed는 Zero Redundancy Optimizer(ZeRO)라는 새로운 솔루션을 통해 훈련 메모리 공간을 줄인다.
메모리 상태가 데이터 병렬 프로세스 전체에 복제되는 기본 데이터 병렬 처리와 달리 ZeRO는 모델 상태와 기울기를 분할하여 상당한 메모리를 절약한다. 또한 활성화 메모리와 조각난 메모리도 줄인다.
130억 개의 매개변수 모델을 실행할 수 있으며, 이는 기존 접근 방식보다 10배 더 큰 동시에 경쟁력 있는 처리량을 얻을 수 있다.
확장성
3D 병렬화 지원 : 데이터 병렬화 + 모델 병렬화 + 파이프라인 병렬화
- DeepSpeed의 3D 병렬 처리는 수조 개의 매개변수로 모델을 실행할 수 있는 시스템 지원을 제공한다.
- DeepSpeed는 15억에서 천억에 이르는 다양한 크기의 모델에 대해 최대 10배 더 빠르게 대형 모델을 보다 효율적으로 실행할 수 있다.
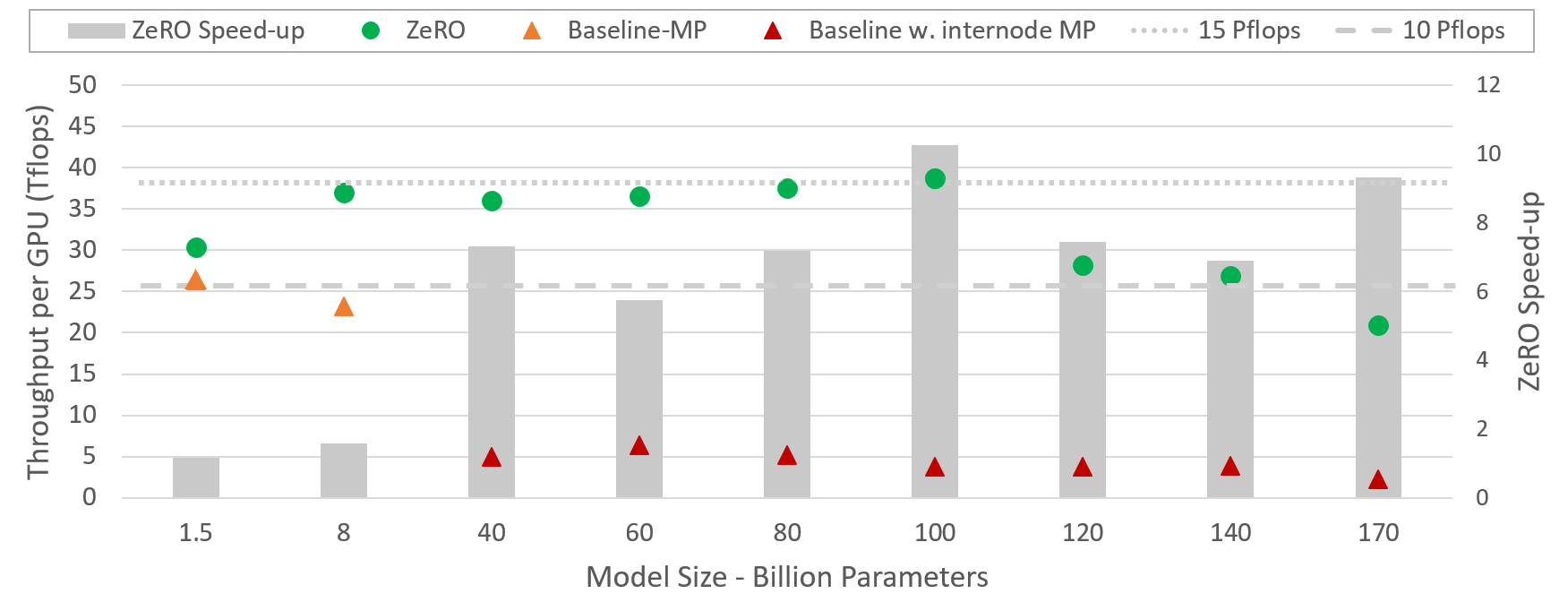
커뮤니케이션 효율성
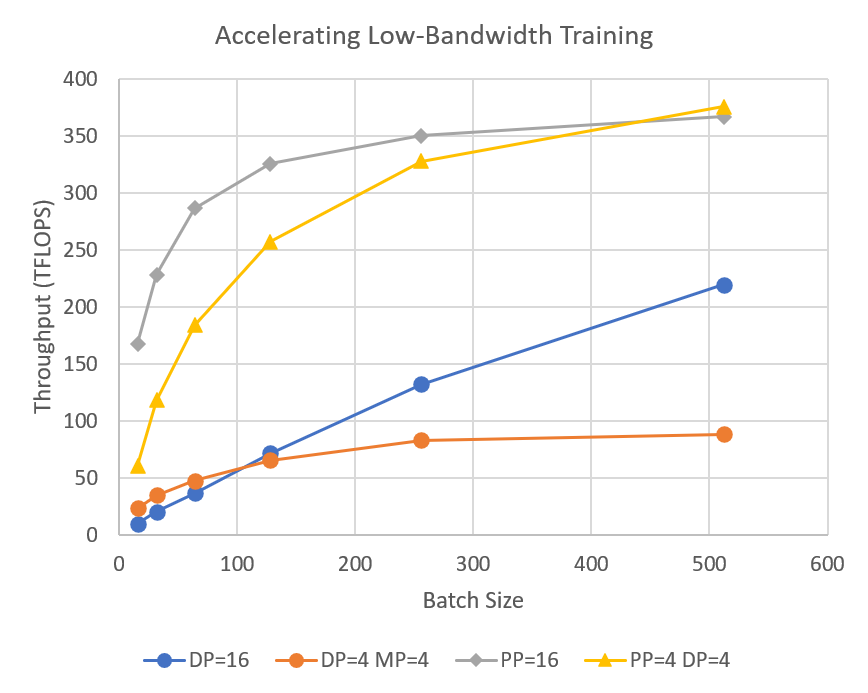
DeepSpeed의 파이프라인 병렬 처리는 분산 교육 중에 통신량을 줄여 사용자가 네트워크 대역폭이 제한된 클러스터에서 수십억 개의 매개변수 모델을 2~7배 빠르게 교육할 수 있도록 한다.
1비트 Adam, 0/1 Adam 및 1비트 LAMB는 통신량을 최대 26배까지 줄이는 동시에 Adam과 유사한 수렴 효율성을 달성하여 다양한 유형의 GPU 클러스터 및 네트워크로 확장할 수 있습니다. 1비트 Adam 블로그 게시물 , 1비트 Adam 튜토리얼 , 0/1 Adam 튜토리얼 , 1비트 LAMB 튜토리얼
데이터 효율성
DeepSpeed Data Efficiency Library는 커리큘럼 학습을 통한 효율적인 데이터 샘플링과 무작위 계층 토큰 드롭을 통한 효율적인 데이터 라우팅을 제공한다.
긴 시퀀스 길이 지원
DeepSpeed는 희소 어텐션 커널을 제공한다. 이는 텍스트, 이미지, 사운드 등 모델 입력의 긴 시퀀스를 지원하는 도구적 기술입니다. 고전적인 조밀한 트랜스포머와 비교하여 훨씬 더 긴 입력 시퀀스에 전원을 공급 하고 비슷한 정확도로 최대 6배 더 빠른 실행을 얻는다. 또한 1.5–3배 더 빠른 실행으로 최신 희소 구현을 능가한다.
효율성을 위한 빠른 수렴
DeepSpeed는 고급 하이퍼파라미터 튜닝 및 LAMB 와 같은 대규모 배치 크기 옵티마이저를 지원한다 . 이를 통해 모델 교육의 효율성이 향상되고 원하는 정확도로 수렴하는 데 필요한 샘플 수가 줄어든다.
특징
- 혼합 정밀도를 사용한 분산 교육
- 16비트 혼합 정밀도
- 단일 GPU/다중 GPU/다중 노드
- 모델 병렬성
- 사용자 지정 모델 병렬 처리 지원
- Megatron-LM과 통합
- 파이프라인 병렬성
- 3D 병렬성
- Zero Redundancy 옵티마이저
- 옵티마이저 상태 및 기울기 분할
- 활성화 파티셔닝
- 상수 버퍼 최적화
- 연속 메모리 최적화
- 제로 오프로드
- 모델 훈련을 위해 CPU/GPU 메모리를 모두 활용
- 단일 GPU에서 10B 모델 교육 지원
- 초고속 고밀도 변압기 커널
- 희박한 관심
- 메모리 및 컴퓨팅 효율적인 스파스 커널
- Dense보다 10배 긴 시퀀스 지원
- 다양한 희소 구조에 대한 유연한 지원
- 1비트 Adam , 0/1 Adam 및 1비트 LAMB
- 맞춤형 커뮤니케이션 콜렉티브
- 통신량 최대 26배 절약
- 추가 메모리 및 대역폭 최적화
- 스마트 기울기 누적
- 통신/계산 오버랩
- 교육 기능
- 간소화된 교육 API
- 그라디언트 클리핑
- 혼합 정밀도로 자동 손실 스케일링
- 트레이닝 옵티마이저
- 융합된 Adam 옵티마이저 및 임의torch.optim.Optimizer
- 메모리 대역폭 최적화 FP16 옵티마이저
- LAMB 옵티마이저를 사용한 대규모 배치 훈련
- ZeRO Optimizer를 사용한 메모리 효율적인 교육
- CPU 아담
- 불가지론적 체크포인팅 교육
- 고급 매개변수 검색
- 학습률 범위 테스트
- 1주기 학습률 일정
- 간소화된 데이터 로더
- 데이터 효율성
- 커리큘럼 학습을 통한 효율적인 데이터 샘플링 및 무작위 계층 토큰 드롭을 통한 효율적인 데이터 라우팅
- GPT-3/BERT 사전 교육 및 GPT/ViT 미세 조정 중 최대 2배의 데이터 및 2배의 시간 절약
- 또는 동일한 데이터/시간에서 모델 품질을 추가로 향상
- 커리큘럼 학습
- 훈련 중 초기에 더 쉽거나 더 간단한 예를 제시하는 커리큘럼 학습 기반 데이터 파이프라인
- 토큰 방식 수렴 속도를 유지하면서 8배/4배 더 큰 배치 크기/학습 속도로 안정적이고 3.3배 더 빠른 GPT-2 사전 교육
- 다른 많은 DeepSpeed 기능을 보완
- 프로그레시브 레이어 드롭
- 효율적이고 강력한 압축 교육
- 사전 교육을 위한 최대 2.5배의 수렴 속도 향상
- 성능 분석 및 디버깅
- 전문가 혼합(MOE)
'AI 인공지능 > LLM' 카테고리의 다른 글
| Code LLM 모델과 평가방식 (0) | 2023.10.19 |
|---|---|
| ChatGPT 탈옥 (DAN 모드) 아직도 가능한가? (0) | 2023.08.04 |
| 효과적인 ChatGPT Prompt Engineering 방법 (0) | 2023.08.02 |
| ChatGPT API를 사용해보자 (0) | 2023.03.06 |
| 센세이션을 불고 온 ChatGPT (0) | 2023.02.20 |


