Good Retry, Bad Retry 장애 스토리
Good Retry, Bad Retry 장애 스토리
정말 좋은 글이기에, 아래 블로그에 있는 내용에 대한 리뷰를 써보고자 한다.
https://medium.com/yandex/good-retry-bad-retry-an-incident-story-648072d3cee6
Good Retry, Bad Retry: An Incident Story
Sometimes, a seemingly simple and obvious solution can lead to a series of problems later on. This is especially true when adding retries.
medium.com
리뷰를 하기에 앞서 초보자들도 이해를 돕기 위해 몇가지 예시는 임의로 추가를 하였고 교정하였음을 알려 드린다.
이런 좋은 글을 공유해 준 블로그 주인 Denis Isaev 님께 감사를 드린다.
간단한 재시작의 발단
간단하고 명백한 해결책이 나중에 나비효과처럼 연쇄적인 문제로 이어질 수 있다.
우리는 보통 Retry 처리를 어떻게 하고 있을까? Python의 requests 모듈을 사용하여 요청하는 예시를 들어보자.
def retry_request(url: str, retry_cnt: int = 3):
try:
response = requests.get(url)
return response
except Exception as e:
if retry_cnt > 0:
return retry_request(url, retry_cnt - 1)
else:
raise e
위의 코드에는 흔히 사용하는 코드일뿐더러 별다른 문제가 없어 보인다. 하지만 이러한 방식에 어떤 문제가 있을까?
그 문제는 바로 재시도 폭풍(Retry Storm) 문제에 직면할 수 있다. (참고: Retry Storm 문제)
재시도 폭풍(Retry Storm)란?
시스템이나 네트워크에서 장애가 발생했을 때 여러 클라이언트(혹은 서비스)가 동시에 재시도 요청을 보내면서, 시스템에 과부하를 유발하는 현상을 말한다.
만약 서비스 장애가 발생하여 서비스가 중단되었다고 가정하면, 지속적인 재시도가 서비스를 압도하고 복구 속도를 늦추게 될 수 있다.
이해를 돕기 위해 동기적 문제에 대하여 알아보자
여러 사람이 동시에 예약 시스템에 접속하여 같은 시간에 예약을 시도하는 상황을 상상해보자.
만약 그 예약 시스템이 이미 서버가 과부하 상태라면, 많은 사용자가 같은 시점에 다시 접속을 시도하면서 대기하게 된다.
이처럼 여러 사람들이 모두 동시에 예약 시스템에 다시 재접속을 시도하면, 서버 시스템에 과부하가 걸리게 된다.
이와 마찬가지로, 동기적 문제는 여러 클라이언트가 동시에 재시도 요청을 보내면서 발생한다.
특히, 서버가 일시적인 문제를 겪고 있을 때 여러 클라이언트는 동일한 시점에 오류를 경험하고 동시에 재시도를 시작하게 된다.
이 경우 백오프(Backoff)가 고정된 방식으로 적용되면, 클라이언트들이 모두 동일한 타이밍에 재시도할 가능성이 높아지게 된다.
해결을 위한 지터(Jitter) 도입
쉽게 설명하자면, 앞의 예시처럼 예약 시스템처럼 동시적으로 한 번에 시도를 하지 않고 클라이언트가 각기 다른 시간에 예약을 시도하면 과부하를 방지할 수 있다.
요청을 고르게 분산시킴으로써 서버의 부하를 줄이는 것이 바로 지터의 개념이다.
이 동기적 문제를 해결하기 위해 지터(Jitter)라는 방법을 사용할 수 있다. 지터는 재시도 간격을 고정된 값이 아니라 무작위(random)로 변동시키는 방법이다.
즉, 각 클라이언트가 재시도할 때 대기 시간을 무작위로 설정하므로 클라이언트들이 동시에 재시도하는 일을 방지할 수 있다.
지터를 사용하는 방법은 재시도 간격을 설정할 때, 그 값을 고정하지 않고 특정 범위 내에서 무작위로 결정하는 것이다.
예를 들어, 재시도 간격이 2초라고 할 때 지터를 적용하면 실제로는 1초에서 3초 사이의 무작위 대기 시간이 적용될 수 있다.
왜 지터가 효율적인가?
지터가 효율적인 이유는 동기적 문제를 방지하여 서버의 부하를 고르게 분산시킬 수 있기 때문이다.
동시다발적으로 클라이언트들이 재시도를 시도하는 상황을 피할 수 있기 때문에 서버는 폭발적인 요청을 일시에 받는 대신 더 균등하게 처리할 수 있는 환경이 조성된다. 결과적으로 서버의 성능이 향상되고, 시스템 복구 속도가 단축될 수 있다.
지터를 적용한 코드는 다음과 같다.
while True:
# 지수적 백오프와 지터를 결합한 코드
delay = min(DELAY_BASE_MS * pow(2, attempt_count), MAX_DELAY_MS)
delay = random_between(0, delay)
sleep(delay)
그러나 지터만으로 충분할까? 지수적 백오프의 한계
3년 후, 시스템은 500개의 마이크로서비스로 성장했다.
모든 서비스 간 호출은 재시도의 대상이 되었고, 공통 라이브러리를 사용하여 지수 백오프 및 지터를 올바르게 구현하고 있었다.
그러나 어느 날, 백엔드 전체가 한 시간 동안 다운되는 사건이 발생했다.
릴리스는 10분 이내에 롤백되었지만, 백엔드는 여전히 복구되지 않았다.
많은 서비스의 CPU 사용률이 100%에 달했고, 20분 후 팀은 백엔드에서 부하를 완전히 제거해야만 시스템을 살릴 수 있음을 깨달았다.
그들은 속도 제한기를 사용해 트래픽을 사용자의 1%로 줄이고 점차적으로 부하를 늘려가며 복구 작업을 수행했다.
결국, 부하를 점진적으로 늘리는 방식으로 복구에 성공할 수 있었다.
지수적 백오프의 문제점은 무엇이었을까?
서비스 대시보드를 살펴본 결과, 복구 기간 동안 서비스가 평소보다 9배의 부하를 처리하고 있었다는 점을 발견했다.
이 문제를 살펴보며 글쓴이는 장기간의 회복 증상이 준안정적 고장 상태(Metastable Failure State, MFS) 문제와 유사하다는 것을 관찰했다.
지수적 백오프는 단순히 요청을 지연시키는 방식으로 동작한다.
따라서 단기간의 다운타임이나 빠른 자동 확장에는 효과적일 수 있지만, 특정 다운타임 임계값 이후에는 서버 부하를 줄이는 데 효과가 없었다. 결국 서버는 재시도로 인해 압도되었다.
재시도의 근본적인 문제는 무엇일까?
근본적으로 생각해보자. 재시도와 부하 증폭이 왜 문제였을까?
재시도가 있었다는 것은 곧 오류가 있었다는 뜻이며, 이는 시스템이 인프라적으로 충분하지 않았음을 의미한다.
문제의 본질은 재시도가 아니라, 재시도가 발생할 수밖에 없는 시스템적 취약성에 있었다.
재시도의 주요 문제는 다음과 같다.
- 재시도로 인해 부하가 증가하여 시스템 복구가 지연된다.
- 재시도가 없을 경우 시스템은 더 빠르게 복구될 수 있지만, 이는 일시적인 오류 상황에서 대응할 수 없게 된다.
그렇다면 재시도를 없애는 것이 타당한가?
재시도가 없는 시스템은 더 빨리 복구될 수 있다.
그러나 현실적으로 정상적인 시스템에서도 가끔씩 서버 오류가 발생할 수 있다.
재시도는 이러한 상황에서 요청을 성공으로 이어지게 하는 중요한 역할을 한다.
방법: 재시도 회로 차단기와 재시도 임계치 제한
결론적으로, 서비스가 정상일 때와 문제가 발생했을 때를 구분하는 것이 필요하다.
서비스가 정상이라면 오류가 일시적일 가능성이 높으므로 재시도가 가능하다.
반면, 서비스에 문제가 있다면 재시도를 중지하거나 최소화해야 한다.
이 경우 사용할 수 있는 두 가지 기술적인 방법은 다음과 같다.
- 재시도 회로 차단기(Circuit Breaker)
- 서비스 클라이언트는 서비스의 오류 비율이 특정 임계값(예: 10%)을 초과하면 재시도를 완전히 비활성화한다.
- 이후 오류 비율이 임계값 아래로 떨어지면 재시도가 재개된다.
- 이를 통해 서비스에 문제가 있을 때 추가 부하를 방지할 수 있다.
- 콜센터에 100통의 전화가 걸려왔다고 가정해보자.
- 만약 10통 이상의 전화에서 "상담원 연결 실패"가 발생하면(10% 실패율), 시스템은 자동으로 "지금은 전화가 많아 재시도하지 말고 잠시 후에 다시 걸어주세요."라는 안내 메시지만 출력하게 된다.
- 이후 1분 동안 실패율이 10% 미만으로 떨어지면 다시 정상적으로 재시도가 가능해진다.
- 재시도 임계치 제한(Adaptive Retry Limit)
- 재시도를 항상 허용하되, 예산 범위 내에서 제한한다.
- 예를 들어, 성공적인 요청 수의 10%까지만 재시도를 허용한다.
- 콜센터에 성공적으로 연결된 전화가 100통이라고 가정하자.
- 이때 재시도는 성공한 전화 수의 10%인 10통까지만 허용된다.
- 즉, 첫 시도에서 성공적으로 처리된 100통의 전화가 있다면, 추가 재시도는 10통까지만 허용된다.
- 이를 통해 콜센터가 과부하되는 상황을 방지할 수 있다.
무엇을 사용해야 할까? 여러 가지 시뮬레이션
글쓴이는 시뮬레이션에서 회로 차단기와 재시도 임계치를 비교했다.
그 결과, 회로 차단기가 재시도 임계치보다 더 위험할 수 있다는 점이 밝혀졌다.
- 회로 차단기는 하나의 샤드(Shard)만 실패하더라도 서비스 전체 요청을 조기에 차단해버렸다.
- 이는 서비스의 일부만 문제가 있는 상황에서도 전체 서비스가 문제가 있는 것처럼 보이게 만들었다.
따라서 회로 차단기는 재시도 임계치보다 높은 오류 임계값(예: 50%)이 필요하며, 이는 허용 가능한 부하 증폭이 더 높아질 수 있음을 의미한다. 궁극적으로 팀은 회로 차단기를 재시도 예산 기법과 결합해 사용하는 것이 적절하다는 결론을 내렸다.
추가 조사를 통해 팀은 마감일 전파(Deadline Propagation)가 실행 중에 많은 요청을 종료시키고 있었다는 사실도 발견했다.
하지만 이 요청들 중 상당수는 서버에 도달하기도 전에 재시도 요청으로 인해 CPU 자원을 소모하고 있었다.
결론적으로 마감일 전파는 재시도 예산 기법을 대체하기보다는 보완하는 방식으로 사용되어야 한다.
결론
사고 검토가 완료된 지 몇 달 후, 플랫폼 팀은 임계값 10%를 기준으로 하는 재시도 임계치 제한 방법을 채택한다.
이후 또 다른 사고가 발생했지만, 재시도로 인한 부하 증폭은 관찰되지 않았다.
이 사고 검토를 통해 글쓴이는 다음과 같은 점을 배웠다.
- 단순히 "일시적인 오류가 발생하면 재시도를 추가"하는 것은 위험한 접근 방식이다.
- 지수 백오프와 지터 기술을 사용하더라도 관련된 위험에 대해 심층적으로 이해할 필요가 있다.
결국, 재시도 증폭 문제를 방지하기 위해서는 지수 백오프와 지터, 재시도 회로 차단기, 재시도 임계치 제한, deadline propagation 기법을 조합해 사용하는 것이 필요하다는 점을 알게 되었다고 한다.
시뮬레이션
부록1. 지수 백오프 (Exponential Backoff)
지수 백오프는 지터가 아니다.
지수 백오프 (Exponential Backoff)란?
특정 작업(예: 네트워크 재시도)이 실패했을 때, 재시도 간의 대기 시간을 점진적으로 늘리는 방식이다.
대기 시간이 지수 함수적으로 증가한다.
예)
- 첫 번째 실패 후 재시도: 1초 대기
- 두 번째 실패 후 재시도: 2초 대기
- 세 번째 실패 후 재시도: 4초 대기
- 이후 계속 배수로 증가 (8초, 16초 등).
MAX_RETRY_COUNT = 3
MAX_DELAY_MS = 1000
DELAY_BASE_MS = 50
attempt_count = 0
max_attempt_count = MAX_RETRY_COUNT + 1
while True:
result = do_network_request(...)
attempt_count += 1
if result.code == OK:
return result.data
if attempt_count == max_attempt_count:
raise Error(result.error)
delay = min(DELAY_BASE_MS * pow(2, attempt_count), MAX_DELAY_MS)
sleep(delay)부록2. 지수 백오프 (Exponential Backoff) 시뮬레이션
- 각 클라이언트는 단일 요청을 생성하고, 100ms 시간 초과로 응답을 기다림.
- 서버 다운타임은 0.5초에서 1초 사이의 간격으로 에뮬레이션됨.
- 서버는 모든 요청(100%)에 대해 의도적으로 오류를 반환함.
- 일반적인 네트워크 왕복 시간은 15ms(10ms 기본 + 5ms 추가 지연)로 설정됨.
- 요청 실패(오류 또는 시간 초과) 시 클라이언트는 최대 3번 재시도하여 총 4번의 요청을 수행함.
아래는 단순 재시작만 하였을 경우 서버 RPS가 4배로 증가했음을 보여줍니다. (부하증폭)

다음은 지수 백오프를 사용한 결과이다.
부하 증폭을 크게 줄였기 줄였지만 서버 부하가 급증하는 것은 이전과 다를바 없다.
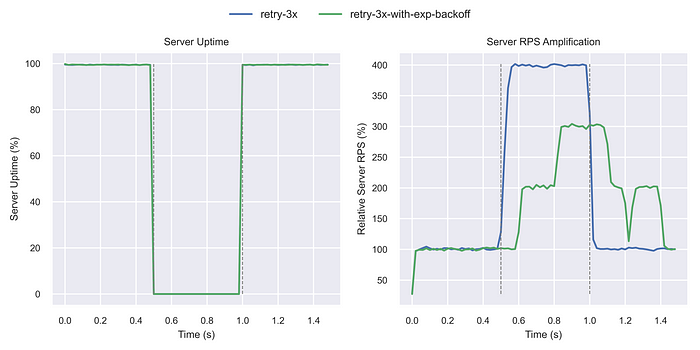
부록 3. 폐쇄 루프 시스템 (Closed-Loop System)
클라이언트 수에 제한을 추가하였다. 즉, 서버 응답을 기다리거나 재시도 사이에 잠자고 있는 클라이언트 수이다.
서버 다운타임 동안 부하 증폭이 상당히 감소하였다. 지수적 백오프와 단순 재시도 간의 차이가 훨씬 더 두드러졌다.

- 재시도 지연 증가: 재시도 간의 대기 시간이 기하급수적으로 늘어나면서 요청 지연 시간이 증가함.
- 리틀의 법칙: 지연 시간이 5배 증가하면 활성 클라이언트 수도 5배 증가.
- 결과적으로, 시스템은 활성 클라이언트 수의 한계에 더 빨리 도달.
- 서버 부하 감소: 최소 하나의 요청이 완료될 때까지 새로운 요청이 생성되지 않으므로 서버 부하가 감소.
- RPS 패턴(사인파):
- t=0.5초: 첫 번째 오류 후 모든 클라이언트가 동기화되어 동일한 지연(0.1초)을 기다림.
- t=0.6초: 활성 클라이언트 수 한계에 도달, 새 요청 전송 중단.
- t=0.8초: 재시도 대기 중인 클라이언트가 새 요청을 생성하지 못해 RPS가 감소.
- 비효율적인 서버 부하: 클라이언트 요청이 동기화되어 서버 리소스를 효율적으로 사용하지 못함.
- 복구 후 RPS 급증:
- t=1.25초: 대기 중이던 클라이언트가 한꺼번에 요청을 보내면서 RPS 급증.
- 이는 동기화와 제한 해제로 인해 발생한 현상.
결론적으로, 클라이언트 재시도 동기화와 지연 증가가 비효율성과 부하 변동을 초래함.
(결국 재시도 요청들이 동기화되면서 나중에 한꺼번에 부하가 급격히 증가한다는 뜻)
부록 4. 지터 및 클라이언트 동기화

- 지터 효과:
- 부하 분산: 다운타임 동안 서버 부하가 더 고르게 분산됨.
- 효율성 증가: CPU 유휴 상태가 줄어들고, 다운타임 후 피크 부하 증폭이 더 빠르게(t=1.1초) 발생하며 지속 시간도 짧아짐.
- 결과적으로, 시스템 복구 속도가 빨라짐.
- 시뮬레이션 결과:
- CPU 여유 공간(헤드룸)이 줄어들수록(4배 → 2배), 지터의 효과가 더욱 뚜렷해짐.
- 클라이언트 타이밍 변화와 결합할 때, 지터가 부하 분산에 큰 영향을 미침.
부록 5. 재시도에 대한 지수 백오프 (Exponential Backoff) 지연
- 서버 다운타임 연장 실험:
- 서버 가동 중지 시간을 [0.5초; 1.0초]에서 [0.5초; 1.5초]로 늘려 지연 효과를 검증.
- 오픈 루프 시스템 실험:
- 단순 재시도 vs. 지수 백오프 비교.
- 지수 백오프에서도 여전히 4배 부하 증폭 발생, 하지만 더 늦게 발생함.
- 이전 시뮬레이션에서 효과를 인지하지 못했던 이유는 다운타임이 짧았기 때문임.
- 폐쇄 루프 시스템 요소 추가:
- 활성 클라이언트 수 제한을 도입하여 부하 증폭을 지연.
- 한도를 높이면(정상 RPS의 30% → 40%), 다시 부하 증폭 발생.
- 결론:
- 단순히 한계를 설정하는 것만으로는 부하 증폭을 해결하기 충분하지 않음.
- 한도가 적절해야 하지만, 실제 시스템에서 이를 보장하기 어려움.
- 지수 백오프는 단순 재시도와 동일한 부하 증폭을 초래하나, 더 늦게 나타남.

다음과 같이 이 활성 클라이언트 한도를 정상 RPS의 30%에서 40%로 높이면 상황이 바뀌게 됨.

결론적으로, 부하 증폭을 완전히 막으려면 지수 백오프와 한계 설정 외에 추가적인 제어가 필요함.
부록 6. 재시도 느린 복구
- 시뮬레이션 설정 변경:
- 클라이언트 타임아웃을 100ms, 200ms, 300ms 중 무작위 값으로 설정해 실제 시스템을 더 잘 반영.
- 클라이언트 재시도 횟수를 3회 → 2회로 감소.
- 결과 분석:
- 복구 속도 차이:
- 재시도가 없는 클라이언트는 t=1.5초에 바로 복구.
- 재시도를 사용하는 경우, 오류 해소까지 t=2.3초 소요.
- 이는 지수적 백오프를 사용해도 재시도가 복구 시간을 연장한다는 점을 검증.
- 복구 속도 차이:


부록 7. 재시도 임계치 (Retry Budget) vs 재시도 회로 차단기 (Retry Circuit Breaker)
- 추가된 기술:
- 시뮬레이션에 재시도 예산과 재시도 회로 차단기를 도입.
- 이를 지터와 지수 백오프, 단순 재시도, 재시도가 없는 경우와 비교.
- 복구 속도 개선:
- 재시도 예산(분홍색)과 회로 차단기(갈색)는 서버 과부하를 줄이고 복구 속도를 t=1.25초 → t=1.0초로 단축.
- 부분적 실패 시나리오:
- 서버가 30% 오류를 반환하는 경우를 시뮬레이션.
- 재시도 예산과 회로 차단기가 과부하를 방지했으나, 클라이언트 가동 시간이 감소하는 대가를 치름.
- 재시도 예산의 영향:
- 클라이언트 가동 시간을 늘리지만, 서버에 10%의 추가 부하를 발생시킴.
결론적으로, 재시도 예산과 회로 차단기는 서버 안정성을 높이지만, 클라이언트 가동 시간이나 서버 부하와의 트레이드오프가 존재함.



부록 8. 재시도 임계치 (Retry Budget) vs 회로 차단기 (Request (not Retry) Circuit Breaker)
- 시뮬레이션 조건 변경:
- 모든 요청에 오류를 주입하는 대신, 샤드 오류 시뮬레이션을 도입하여 일부 사용자만 오류를 경험하도록 설정.
- 5개의 데이터베이스 샤드 중 1개 실패로 20% 사용자에 영향을 미치는 시나리오를 설정.
- 회로 차단기 테스트:
- 10% 임계값 설정으로 요청 회로 차단기(밝은 파란색 선) 시뮬레이션.
- 회로 차단기가 작동하여 일정 기간 동안 서비스 요청이 완전히 차단되며 CPU 사용량이 0으로 떨어짐.
- 소량의 트래픽만 통계를 위해 주기적으로 허용되어 그래프에 심박수 모양이 나타남.
- 단일 샤드 장애 시에도 모든 요청에 동일한 페널티 부과됨
- 재시도 임계치 비교:
- 이 시나리오에서 재시도 임계치가 더 나은 옵션임을 확인.
- 50% 임계값 테스트:
- 회로 차단기의 임계값을 50%로 높여 단일 샤드 장애를 평가.
- 상황 악화를 방지했지만, 여전히 부하 증폭 문제를 해결하지 못함.
결론적으로, 샤드 오류 시뮬레이션에서는 회로 차단기가 단일 장애에도 전체 서비스에 영향을 미치며, 재시도 예산이 더 적합한 대안으로 나타남.


부록 9. 마감일 전파 (Deadline Propagation)
Deadline Propagation란?
우리말 IT 용어가 검색해도 잘 나오지 않는다.
간단히 설명하면, 요청을 처리할 시간이 얼마나 남았는지 계속 계산하면서, 남은 시간 안에 요청을 재시도할지 결정하는 방법이다.
시간이 부족하면 중단하고, 시간이 충분하면 재시도 하는 방식이다.
- 시뮬레이션
- 마감일 전파(deadline propagation)를 구현하고 이를 단순 재시도 및 재시도 예산과 비교함
- 결과
- 마감일 전파로 요청을 빠르게 종료하면서 시간당 처리되는 요청이 증가해 증폭이 더 커짐.
- 요청 큐가 짧아지면서 서버가 더 빨리 복구. 그러나, 재시도 예산만큼 효과적이지 않음.
- 추가 조사
- 마감일 전파는 실행 중간에 많은 요청을 종료하지만, 이때 이미 서버 CPU 리소스를 소모한 상태.
- 반면, 재시도 예산은 많은 요청이 서버에 도달하기 전에 차단해 CPU 리소스 낭비를 줄임.
- 결론
- 마감일 전파는 재시도 예산의 대체가 아닌 보완 기술로 적합함.
- 두 기술을 함께 사용하면 효과를 극대화할 수 있음.
결론적으로, 마감일 전파는 큐를 줄이고 복구를 가속하지만, 재시도 예산만큼 CPU 리소스를 효율적으로 관리하지는 못함.
